Clinical Genomics Domain Information Model(s) Project
Contents
Project Scope
Throughout the past decade, the HL7 Clinical Genomics has been developing various artifacts (e.g., informative, DSTU and normative specifications), domain analysis models, storyboards, etc. The approved/trialed/proposed specifications are of different HL7 flavors, i.e., v3, v2, CDA and recently FHIR. These artifacts share some common view of clinical genomic data, but lack semantic alignment at the modeling level. Therefore, it is crucial to have agreed-upon Clinical Genomics Domain Information Model(s) (CG DIMs), which have the following functions:
- The CG DIMs reflect the results of the Domain Analysis Model efforts
- The CG DIMs serve as a single source of semantics with which all standard specifications are aligned
- The CG DIMs are represented in an HL7 standards-independent format, e.g., plain UML
- The CG DIMs are Universal and do not mandate binding to specific vocabularies (these bindings could be present in realm-specific versions of the actual standard specifications)
Project Need
The need for this project stems from lack of Clinical Genomics Domain Information Model(s), as well as from lack of alignment across the current HL7 Clinical Genomics specifications.
Success Criteria
The approval of agreed-upon Clinical Genomics DIMs is obviously the main success criterion. Nevertheless, due to the nature of this domain where knowledge is rapidly changing, an equally-important success criterion is to develop processes by which an ongoing update mechanism is enabled, as followed:
- Top-down update: enable update of the CG DIMs following changes to the CG DAM
- Bottom-up update: enable update of the CG DIMs following changes to the CG standard specifications, based on trial use and lessons learnt by early adopters
As future work, it would be desirable to have model-driven & semi-automated processes that enable the propagation of agreed-upon CG DIMs updates onto the standard specifications (e.g., GTR, v2, FHIR), so that they are all kept in synch with each other. Two possible candidates for this model-driven approach are the MDHT tool and the FHIR development infrastructure, which have the benefit of having CDA-based templates or FHIR genomic resources derived from the CG DIMs more easily.
Requirements
Enable standard representations of
- genomic data relevant to healthcare and well-being of individuals
- associations of discrete genomic data with discrete phenotypic data
- pre-clinical and clinical phenotypes
- observed and interpretive phenotypes
Modeling Discussion
- Tooling alternatives: plain UML editor, MDHT, FHIR
- Modelling goal: harmonize the v3, v2, GTR and FHIR models into an agreed-upon DIM
- Modelling approach:
- develop a list of requirements (should actually be in the DAM)
- compare the various models in light of the requirements
- harmonize the various models so that:
- the harmonized DIM accommodates the requirements
- as much as possible, there is a minimal effort to adjust each model to the harmonized DIM
- Initial comparison comments:
- The overall GTR model is based on a document model (CDA), i.e., header and sections
- The GTR structured data is based on the Clinical Genomics Statement, which is a specialization of the CDA Clinical Statement model
- The FHIR GeneticAnalysis Resource has the class DnaAnalysisDiscreteSequenceVariation that bundles the finding with the interpretation - that has been the subject of ongoing discussions in the HL7 Clinical Genomics group and the conclusion was that it is important to treat the interpretation as a separate observation with its time stamp, method, performer etc., rather than an inherent & single attribute of the finding observation class. To that end, the GTR Clinical Genomics Statement has the interpretation in a separate class associated with the genomic observation
- The v3 models used the locus concept as an organizer for related information, where locus could be a gene, a bio-marker or any DNA region of interest
- The v2 model focuses on constrained v2 lab message to transmit results of genetic testing, where certain fields have to be bound to certain LOINC codes (US Realm)
Draft Models
- Clinical Genomics Statement (component model)
- Click here to view the latest version of the model (now ported to a web-based tool): https://repository.genmymodel.com/amnon.shvo/Clinical-Genomics-DIM
- Click here to view the latest version of the model walk-through: Media:HL7_DIM_CG_R1_I1_2014SEP_Clinical_Genomics_Statement_Model_Walk-Through.docx
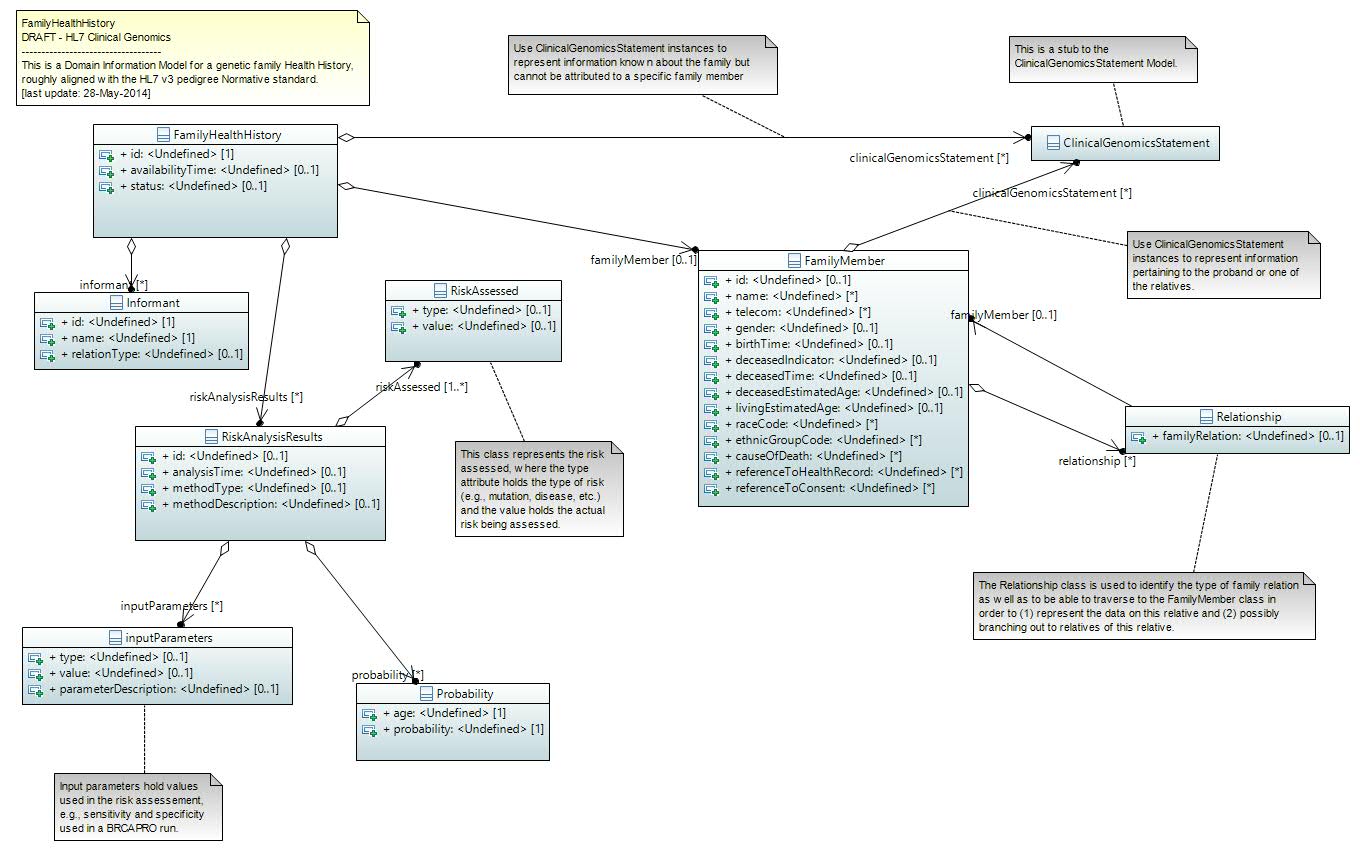
- Family Health History
- Click here to view the latest version: Media:FamilyHealthHistory.JPG
- Click here to view the latest version of the model walk-through: Media:HL7_DIM_CG_R1_I1_2014SEP_Family_Health_History_Model_Walk-Through.docx
- Note: The Family Health History model utilizes the Clinical Genomics Statement component model to represent clinical and genomic information pertaining to the family members
{kind=link}